공유 데이터 (shared data)의 동시 접근 (concurrent access)은 데이터의 불일치 문제 (inconsistency)를 발생시킬 수 있다. 일관성 (consistency) 유지를 위해서는 협력 프로세스 (cooperating process) 간의 실행 순서 (orderly execution)를 정해주는 메커니즘이 필요하다
컴퓨터에서 연산을 할 때에는 항상 데이터를 읽어와서 연산을 하고, 연산 결과를 다시 어딘가로 저장하고 내보내도록 되어 있다.
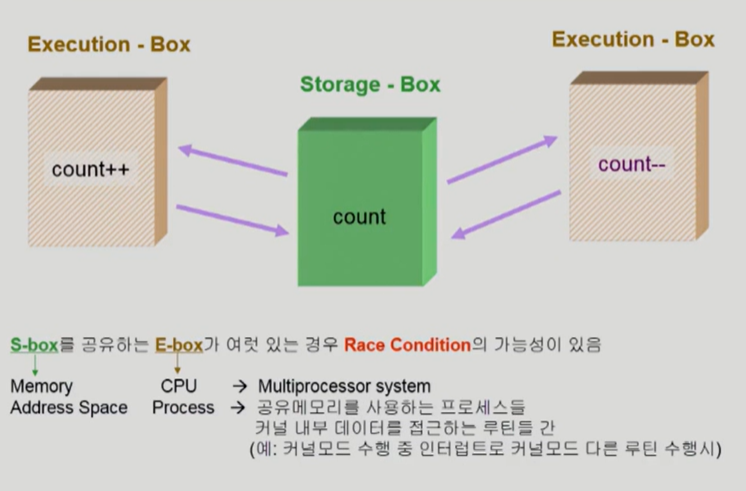
Race Condition
만약 count를 플러스도 하고 마이너스도 했다면 원래 값이 되어야 하지만 마이너스만 반영된다. 이렇게 하나의 데이터를 여럿이 동시에 접근하게 되면 문제가 생긴다. 이러한 문제를 Race Condition, 즉 경쟁 상태라고 한다.
Race Condition 문제는 정말 생기는 것일까 ?
문제가 안 생긴다는 관점에서 이야기를 시작해보자. CPU가 한 개든 여러 개든 문제는 안 생긴다. count와 같은 데이터는 프로세스 내부에 있는 데이터이다. 프로세스는 자기 자신의 주소 공간에 있는 데이터만 접근할 수 있다. 따라서 서로 다른 프로세스 간에는 애초에 데이터를 공유할 수 없다.
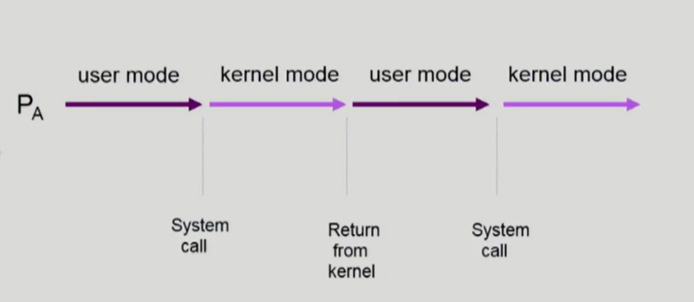
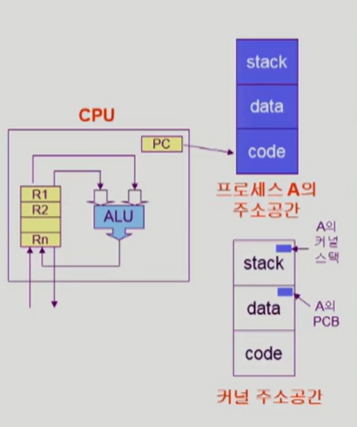
하지만 문제는 운영체제가 끼어드는 경우이다. 이러한 경우는 CPU가 하나만 있어도 문제가 생긴다. 예를 들어 프로세스 A가 CPU에서 실행 중인 경우를 생각해 보자. 프로세스는 본인이 스스로 할 수 없는 일을 운영체제에게 부탁하는 system call을 한다. 프로세스 A가 system call을 하고 운영체제 내 데이터 값을 바꾸려던 찰나 자신의 CPU 할당 시간이 종료되어 CPU는 프로세스 A로부터 프로세스 B로 넘어갔다고 해보자. B 또한 system call을 했는데 우연히 A가 건드리던 똑같은 운영체제 내 데이터 값을 변경하는 상황이 발생했다면 Race Condition 문제가 발생할 수가 있다.
OS에서의 Race Condition
" OS에서 race condition은 언제 발생할까 ? "
1) kernel 수행 중 interrupt 발생하는 경우
Interrupt handler VS kernel
2) process가 system call을 하여 kernel mode로 수행 중, context switch가 일어나는 경우
preempt a process running in kernel ?
➳ 두 프로세스의 address space 간에는 data sharing이 없다.
➳ 그러나 system call을 하는 동안에는 kernel address space의 data를 access 하게 된다. (share)
➳ 이 작업 중간에 CPU를 preempt 해가면 race condition이 발생한다.
If you preempt CPU while in kernel mode,
3) multiprocessor에서 shared memory 내의 kernel data인 경우
CPU가 여러 개 있는 경우 생기는 문제점이다.
방법 1은 운영체제 전체에 lock을 걸어 혼자 독점하는 방법이다. 하지만 방법 2는 운영체제 내 각 데이터 별로 사용 중일 때 lock을 거는 방법이다. 따라서 여러 CPU가 운영체제를 수행 중이어도 해당 데이터를 건드리지만 않는다면 충분히 운영체제 코드를 동시에 실행할 수 있다.
Process Synchronization 문제
공유 데이터 (shared data)의 동시 접근 (concurrent access)은 데이터의 불일치 문제 (inconsistency)를 발생시킬 수 있다. 일관성 (consistency) 유지를 위해서는 협력 프로세스 (cooperating process) 간의 실행 순서 (orderly execution)를 정해주는 메커니즘이 필요하다.
➳ race condition
• 여러 프로세스들이 동시에 공유 데이터를 접근하는 상황
• 데이터의 최종 연산 결과는 마지막에 그 데이터를 다룬 프로세스에 따라 달라진다.
race condition을 막기 위해서는 concurrent process는 동기화 (synchronize) 되어야 한다.
Exampleof a RaceCondition
공유 데이터를 접근하는 코드를 critical-section이라고 부른다.
The Critical-Section Problem
➳ n개의 프로세스가 공유 데이터를 동시에 사용하기를 원하는 경우에 발생한다.
➳ 각 프로세스의 code segment에는 공유 데이터를 접근하는 코드인 critical section이 존재한다.
➳ Problem
• 하나의 프로세스가 critical section에 있을 때 다른 모든 프로세스는 critical section에 들어갈 수 없어야 한다.
Initial Attempts to Solve Problem
➳ 두 개의 프로세스가 있다고 가정한다.
➳ synchronization variable : 프로세스들은 수행의 동기화 (synchronize)를 위해 몇몇 변수를 공유할 수 있다.
프로세스들의 일반적인 구조
critical section 앞(= entry section), 뒤(= exit section)로 어떤 코드를 붙여야 문제를 해결할 수 있을까 ?
다음은 동기화 문제를 해결해주는 알고리즘들을 살펴볼 것이다.
그전에 프로그램적 해결법의 충족 조건을 알아본다.
프로그램적 해결법의 충족 조건
➳ Mutual Exclusion (상호 배제)
• 특정 프로세스가 critial section을 수행 중이면 다른 모든 프로세스들은 그들의 critical section에 들어가면 안 된다.
➳ Progress (진행)
• 아무도 critical section에 있지 않은 상태에서 critical section에 들어가고자 하는 프로세스가 있으면 critical section에 들어가게 해주어야 한다.
➳ Bounded Waiting (유한한 대기)
• 프로세스가 critical section에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 critical section에 들어가는 횟수에 한계가 있어야 한다.
🔮 가정
✔ 모든 프로세스의 수행 속도는 0보다 크다.
✔ 프로세스 간의 상대적인 수행 속도는 가정하지 않는다.
Algorithm 1
synchronization variable로 turn 변수를 사용한다. turn이 1이라면 상대방 차례로 바꾼 것이다. 반드시 한 번씩 교대로 들어가야만 하므로 단점도 존재한다. 프로그램적 해결법의 충족 조건을 보면 mutual exclusion은 충족하지만 progress는 충족하지 않는다.
Algorithm 2
boolean 변수 flag를 활용해 들어가고 싶은 경우 깃발을 들어 의사를 알린다. 상대방의 깃발이 들려있는지 확인하고, 없다면 critical section에 들어갈 수 있다. 누구나 critical section에 들어가서 나올 때에는 깃발을 내려 다른 사람이 들어올 수 있도록 해준다. 프로그램적 해결법의 충족 조건을 보면 Algorithm 1과 마찬가지로 mutual exclusion은 충족하지만 progress는 충족하지 않는다. 깃발은 들고 critical section은 실행하지 않은 상태에서 CPU를 빼앗긴 경우, 새로 CPU를 잡은 다른 프로세스도 깃발을 들기 때문에 서로 끊임없이 양보하는 문제가 있을 수 있다는 것이다.
따라서 Algorithm 1과 Algorithm 2 둘 다 제대로 작동하지 않는다.
Algorithm 3 (Peterson's Algorithm)
깃발도 들고, turn 변수도 사용한다. 즉, 상대방이 깃발을 들고 있으면서 동시에 상대방 차례인 경우에만 기다린다. 프로그램적 해결법의 충족 조건을 모두 충족한다 ! 하지만 비효율적이라는 문제가 있다. 계속 critical section에 들어가지 못하는 경우에 불필요하게 계속 while문을 돌기 때문이다. 이를 busy waiting 혹은 spin lock이라고 한다. 쓸데없이 바쁘게 기다리고, 자원을 낭비한다는 것이다.
Synchronization Hardware
➳ 하드웨어적으로 Test & modify를 atomic 하게 수행할 수 있도록 지원하는 경우 앞의 문제는 간단히 해결된다.
lock이 true라면 애초에 while문을 읽어 내려갈 수가 없다. lock이 풀렸을 때 스스로 lock을 걸고 critical section을 실행해나갈 수 있다.
다음 글에서는 앞서 소개한 세 가지 알고리즘 방식처럼 코드를 직접 작성하지 않고, 좀 더 추상화시킨 process synchronization 문제 해결 방안을 알아본다. 이는 프로그래머로 하여금 도구를 가져다 좀 더 쉽고 효율적으로 문제를 풀 수 있도록 한다.
재귀 문제이다. 처음에 예제가 한 눈에 잘 들어오지 않아서 캡처해서 그림판으로 그려보니 별을 찍는 방법은 쉽게 이해가 갔다. 다음은 크기 27의 패턴이다.
크기 3의 패턴(= 분홍색 정사각형)은 가운데를 제외한 모든 칸에 별이 하나씩 있다.
크기 9의 패턴(= 보라색 정사각형)은 크기 3의 패턴이 가운데를 제외한 모든 칸에 있다.
크기 27의 패턴(= 노란색 정사각형)은 크기 9의 패턴이 가운데를 제외한 모든 칸에 있다.
2차원 배열을 활용하고, boolean 변수를 이용해 공백인지 아닌지 구분하여 별 또는 공백을 자기 자리에 넣어주면 되겠다는 생각을 했다. 뭔가 N을 N/3으로 더 이상 쪼갤 수 없을 때까지 재귀 함수를 계속 호출해서 별을 찍는 느낌은 알겠는데 막상 코드를 짜려니 막막했다 ,, 별을 찍는 재귀 함수의 파라미터를 입력값 N만 두고 생각했는데, 풀이를 찾아보니 2차원 배열의 인덱스이자 별의 위치인 x, y와 공백인지 구분하는 boolean 변수도 파라미터로 둔 것을 보고 힌트를 얻었다.
메인 함수에서 별을 찍을 때에는 StringBuilder를 활용해 한 번에 출력했다.
찾아보니 StringBuilder 보다는 BufferedWriter가 출력이 많은 경우 성능이 더 좋은 편이라고 한다.
Key Point
🔑 재귀 함수를 활용한다.
Java 코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static char[][] stars;
static int N;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
stars = new char[N][N];
drawStar(0, 0, N, false);
StringBuilder result = new StringBuilder();
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
result.append(stars[i][j]);
}
result.append('\n');
}
System.out.println(result);
}
public static void drawStar(int x, int y, int N, boolean blank) {
if (blank) { // 공백인 경우
for (int i = x; i < x+N; i++) {
for (int j = y; j < y+N; j++) {
stars[i][j] = ' ';
}
}
return;
}
if (N == 1) { // 더 이상 쪼갤 수 없는 경우
stars[x][y] = '*';
return;
}
int size = N / 3;
int count = 0;
for (int i = x; i < x+N; i += size) {
for (int j = y; j < y+N; j += size) {
count++;
if (count == 5) drawStar(i, j, size, true);
else drawStar(i, j, size, false);
}
}
}
}
이 고민을 해결하기 위해서 CPU 스케줄링이 필요하다. 여러 종류의 job(=process)이 섞여 있기 때문이다. Interactive job에게는 적절한 response를 제공하는 것이 필요하다. CPU 스케줄링은 CPU와 I/O 장치 등 시스템 자원을 골고루 효율적으로 사용할 수 있도록 한다.
어떤 프로세스는 CPU를 굉장히 오래 사용하고, I/O는 아주 잠깐만 사용한다. 다른 어떤 프로세스는 CPU 잠깐, I/O 잠깐 자주 번갈아 가면서 사용하기도 한다. 이처럼 항상 상황은 다르다. 주로 과학 계산과 같이 연산량이 많이 필요한 프로그램은 CPU를 오래 사용하고, 사람과 Interaction이 많은 프로그램은 CPU와 I/O가 번갈아가면서 사용된다. 아래 CPU-burst Time의 분포를 보면 이를 확인할 수 있다.
CPU-burst Time의 분포
위 그래프에서 보다시피 프로세스는 특성에 따라 두 종류로 나눈다. CPU를 길게 쓰는 프로세스를 CPU bound job(= CPU bound process), I/O가 중간에 많이 끼어들어서 CPU를 짧게 씩 쓰는 프로세스를 I/O bound job(= I/O bound process)이라고 한다.
프로세스의 특성 분류
➳ I/O-bound process
• CPU를 잡고 계산하는 시간보다 I/O에 많은 시간이 필요한 job
• many short CPU bursts
➳ CPU-bound process
• 계산 위주의 job
• few very long CPU bursts
그럼 둘 중 CPU를 누구한테 먼저주어야 할까 ? 준다면 얼마만큼 주어야 할까 ?
이 고민을 해결하기 위해서 CPU 스케줄링이 필요하다. 여러 종류의 job(=process)이 섞여 있기 때문이다. Interactive job에게는 적절한 response를 제공하는 것이 필요하다. CPU 스케줄링은 CPU와 I/O 장치 등 시스템 자원을 골고루 효율적으로 사용할 수 있도록 한다.
CPU Scheduler & Dispatcher
" CPU Scheduler "
➳ Ready 상태의 프로세스 중에서 이번에 CPU를 줄 프로세스를 고른다.
" Dispatcher "
➳ CPU의 제어권을 CPU scheduler에 의해 선택된 프로세스에게 넘긴다.
➳ 이 과정을 context switch(문맥 교환)라고 한다.
CPU 스케줄링이 필요한 경우는 프로세스에게 다음과 같은 상태 변화가 있는 경우이다.
1) Running ➳ Blocked (e.g. I/O 요청하는 system call)
2) Running ➳ Ready (e.g. 할당시간만료로 timer interrupt)
3) Blocked ➳ Ready (e.g. I/O 완료 후 interrupt)
4) Terminate
1), 4)의 경우는 nonpreemptive(= 강제로 빼앗지 않고 자진 반납)
All other scheduling is preemptive (= 강제로 빼앗음)
Scheduling Criteria
Performance Index (= Perrformance Measure, 성능 척도)
✔ CPU utilzation (이용률)
Keep the CPU as busy as possible
✔ Throughput (처리량)
# of processes that complete their execution per time unit
✔ Turnaround time (소요시간, 반환시간)
amount of time to execute a particular process
✔ Waiting time (대기 시간)
amount of time a process has been waiting in the ready queue
✔ Response time (응답 시간)
amount of time it takes from when a request was submitted until the first response is produced, not output
(for time-sharing environment)
이용률과 처리량은 높을수록 좋다. 시간과 관련된 세 가지 성능 척도는 낮을수록 좋다.
Scheduling Algorithms
FCFS (First-Come First-Served)
SJF (Shortest-Job-First)
SRTF (Shortest-Remaining-Time-First)
Priority Scheduling
RR (Round Robin)
Multilevel Queue
Multilevel Feedback Queue
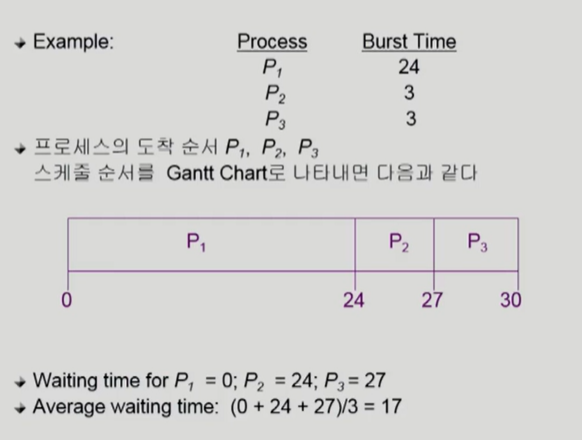
FCFS (First-Come First-Served)
먼저 온 순서대로 처리해 준다. 강제로 빼앗지 않는 nonpreemptive이다. 인간 세상에서는 널리 쓰이는 방법이지만, CPU 스케줄링에서는 대단히 효율적이지 못하다. 위 예제를 보면 성능 척도 중 하나인 waiting time의 평균은 17초이다. 만약 CPU를 짧게 쓰는 프로세스가 먼저 도착했다면 어떻게 될까 ?
똑같은 세 개의 프로세스가 똑같이 선착순으로 왔지만 이번엔 waiting time이 굉장히 짧아졌다.
CPU를 오래 쓰는 프로세스가 먼저 도착한 바람에 CPU를 짧게 쓰는 프로세스가 아주 오래 기다려야 하는 안 좋은 효과를 Convoy effect라고 한다.
SJF (Shortest-Job-First)
➳ 각 프로세스의 CPU burst time을 가지고 스케줄링에 활용한다.
➳ CPU burst time이 가장 짧은 프로세스를 제일 먼저 스케줄 한다.
💡 Two schemes :
1) Nonpreemptive
일단 CPU를 잡으면 이번 CPU burst가 완료될 때까지 CPU를 선점 (preemption)하지 않는다.
2) Preemptive
현재 수행 중인 프로세스의 남은 burst time 보다 더 짧은 CPU burst time을 가지는 새로운 프로세스가 도착한다면 CPU를 빼앗긴다. 이 방법을 Shortest-Remaining-Time-First (SRTF)이라고도 부른다.
" SJF is optimal "
주어진 프로세스에 대해 minimum average waiting time을 보장한다. optimal은 최적의 방법이라는 뜻이다. 즉, 다른 어떤 CPU 스케줄링 알고리즘을 쓰더라도 SJF보다 대기 시간의 평균을 더 짧게 할 수는 없다는 의미이다. SJF는 두 가지로 나뉘지만 제일 optimal 한 방법은 Preemptive 버전인 SRTF이다.
Example of Non-Preemptive SJF
Example of Preemptive SJF
그러나 SJF는 치명적인 약점을 가지고 있다. 바로 starvation을 발생시킬 수 있다는 점이다. SJF는 극도로 효율성을 중시하다 보니 짧은 프로세스에게 무조건 우선순위를 준다. 따라서 long job, 즉 CPU를 길게 쓰는 프로세스는 영원히 CPU를 못 얻을 수도 있다. Queue가 계속 쌓일 수 있기 때문이다. 어떤 프로세스가 10초라고 한다면 앞에 계속 1초짜리 10000개, 3초짜리 10000개가 속속히 도착을 한다면 10초가 걸리는 프로세스는 아예 기회가 없을 수 있다는 것이다.
SJF는 CPU를 짧게 쓰는 프로세스한테 준다고 했다. 하지만 누가 짧게, 누가 길게 쓰는지 처음에 알 수가 없다. 짧게 쓴다고 했는데 막상 계속 길게 쓰는 경우가 있고, 길게 쓴다고 했는데 막상 짧게 쓰고 I/O를 하러 가버리는 경우도 있기 때문이다. 즉, 얼마큼 CPU를 사용한 후 I/O를 하러 갈 것인지, CPU burst를 예측하기 힘들다는 것이다. 정확히는 예측하기 어렵지만 과거의 CPU burst 이력을 보고 다음번의 CPU burst를 예측하는 방법을 알아보자 !
다음 CPU Burst Time의 예측
다음번 CPU burst time을 어떻게 알 수 있을까?
추정(estimate)만이 가능하다. 과거의 CPU burst time을 이용해서 추정한다. (exponential averaging)
1. t는 실제 과거의 CPU burst 값이다. n은 이미 과거에 지나간 것으로, n번째 CPU burst 값이 얼마였는지 알려준다.
2. 𝛕 는 예측값이다. n+1번째의 CPU Burst 값을 예측하는 것이다.
3. α는 어느 정도 가중치를 두어 반영할 것인지를 결정한다.
4. n번째 실제 CPU Burst 값과 n번째 CPU Burst를 예측한 값에 어느 정도 가중치를 두어 두 값을 더하는 것이다.
Priority Scheduling
➳ A priority number (integer) is associated with each process`
➳ Starvation : low priority processes may never execute
🌀 Solution
➳ Aging : as time progresses increase the priorityof the process
SJF의 문제점인 Starvation을 해결하는 방법은 Aging이다. Aging은 나이 든 프로세스를 우대한다. 먼저 온 프로세스는 시간이 지날수록 우선순위를 높여주는 것이다. 다음은 실제 현재 CPU Scheduling에서 가장 많이 사용하는 방법의 근간이 되는 알고리즘, Round Robin을 알아보자 !
Round Robin (RR)
➳ 각 프로세스는 동일한 크기의 할당 시간 (time quantum)을 가진다.
• 일반적으로는 10-100 milliseconds
➳ 할당 시간이 지나면 프로세스는 선점(preempted)당하고, ready queue의 제일 뒤에 가서 다시 줄을 선다.
➳ n개의 프로세스가 ready queue에 있고 할당 시간이 q time unit인 경우 각 프로세스는 최대 q time unit 단위로 CPU 시간의 1/n을 얻는다.
• 어떤 프로세스도 (n-1)q time unit 이상 기다리지 않는다.
➳ Performance
• q large : FCFS
• q small : context switch 오버헤드가 커진다.
long job과 short job이 섞여있기 때문에 Round Robin을 사용하는 것이 효율적인 것이다. 만약 long job만 있거나, short job만 있도록 통일된 프로세스를 생각해 보자. 만약 똑같이 5분 걸리는 프로세스가 100개라고 한다면 Round Robin 알고리즘보다는 그냥 5분씩 끝까지 처리해주는 것이 더 나을 것이다.
Multilevel Queue
" Ready Queue를 여러 개로 분할한다. "
➳foreground(interactive)
➳ background (batch - no human interaction)
" 각 큐는 독립적인 스케줄링 알고리즘을 가진다. "
➳foreground - RR
➳ background - FCFS
" 큐에 대한 스케줄링이 필요하다. "
➳ Fixed priority scheduling
• serve all from foregroundthen from background
• possibility of starvation
➳ Time slice
• 각 큐에 CPU time을 적절한 비율로 할당한다.
• e.g. 80% to foreground in RR, 20% to background in FCFS
Multilevel Feedback Queue
➳ 프로세스가 다른 큐로 이동이 가능하다.
➳ 에이징 (aging)을 이와 같은 방식으로 구현할 수 있다.
➳ Multilevel-feedback-queue scheduler를 정의하는 파라미터들
• Queue의 수
• 각 큐의 scheduling algorithm
• Process를 상위 큐로 보내는 기준
• Process를 하위 큐로 내쫓는 기준
• 프로세스가 CPU 서비스를 받으려 할 때 들어갈 큐를 결정하는 기준
Example ofMultilevelFeedbackQueue
위의 사진은 Multilevel Feedback Queue의 한 예이다. 제일 우선순위가 높은 맨 위 큐에서 프로세스가 끝나지 않았다면 그다음 큐로 내려가는 방식을 표현한 것이다. Round Robin만 사용하는 것이 아니라 상황에 맞게 이런 식으로도 사용을 한다. I/O Bound, 즉 CPU를 빨리 쓰려는 프로세스를 빨리 걸러내서 처리를 하는 효과가 있다.
➳ Three queues
• Q0 : time quantum 8 milliseconds
• Q1 : time quantum 16 millisseconds
• Q2 : FCFS
➳ Scheduling
• new job이 queue Q0으로 들어간다.
• CPU를 잡아서 할당 시간 8 milliseconds 동안 수행한다.
• 8 milliseconds 동안 다 끝내지 못했으면 queue Q1으로 내려간다.
• Q1에 줄 서서 기다렸다가 CPU를 잡아서 16ms 동안 수행한다.
• 16 ms에 끝내지 못한 경우 queue Q2로 쫓겨난다.
특수한 CPU 스케줄링
지금까지는 한 CPU가 있는 환경에서의 CPU 스케줄링 알고리즘에 대해 알아보았다.
지금부터는 특수한 경우의 CPU 스케줄링을 알아본다.
Multiple-Processor Scheduling
➳ CPU가 여러 개인 경우 스케줄링은 더욱 복잡해진다.
➳ Homogeneous processor인 경우
• Queue에 한 줄로 세워서 각 프로세서가 알아서 꺼내 가도록 할 수 있다.
• 반드시 특정 프로세서에서 수행되어야 하는 프로세스가 있는 경우에는 문제가 더 복잡해진다.
➳ Load sharing
• 일부 프로세서에 job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘이 필요하다.
• 별개의 큐를 두는 방법 vs 공동 큐를 사용하는 방법
➳ Symmetric Multiprocessing (SMP)
• 각 프로세서가 각자 알아서 스케줄링을 결정한다.
➳ Asymmetric multiprocessing
• 하나의 프로세서가 시스템 데이터의 접근과 공유를 책임지고 나머지 프로세서는 거기에 따른다.
Real-Time Scheduling
Real-Time OS는 정해진 시간 안에 어떠한 일이 반드시 종료됨이 보장되어야 하는 실시간시스템을 위한 OS이다. 따라서 해당 deadline을 만족시키는 것이 중요하다.
➳ Hard real-time systems
• Hard real-time task는 정해진 시간 안에 반드시 끝내도록 스케줄링을 해야 한다.
➳ Soft real-time computing
• Soft real-time task는 일반 프로세스에 비해 높은 priority를 갖도록 해야 한다.
Thread Scheduling
➳ Local Scheduling
• User level thread의 경우 사용자 수준의 thread library에 의해 어떤 thread를 스케줄 할지 결정한다.
➳ Global Scheduling
• Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케줄러가 어떤 thread를 스케줄할지 결정한다.
User level thread는 운영체제가 thread의 존재를 모르고, 사용자 본인이 내부에 thread를 여러 개 두는 것이다. Kernel level thread는 운영체제가 thread의 존재를 알고, 운영체제가 직접 CPU 스케줄링에 관여한다.
Algorithm Evaluation
물론 성능 척도가 좋은 것이 좋은 CPU 스케줄링 알고리즘이다. 그렇다면 성능 척도를 어떻게 구해서 알고리즘을 어떻게 평가할까? 알고리즘 평가 방법을 알아보자 !
➳Queueing models
• 확률 분포로 주어지는 arrival rate와 service rate 등을 통해 각종 performance index값을 계산한다.
• 복잡한 수식을 계산하는 대단히 이론적인 방법이다.
• 현재 CPU Scheduling에서 사용하지는 않는다.
➳Implemetation (구현) & Measurement (성능 측정)
• 실제 시스템에 알고리즘을 구현하여 실제 작업 (workload)에 대해 성능을 측정하여 비교한다.
fork() System Call이 새로운 프로세스를 생성한다. 부모를 그대로 복사 (OS data except PID + binary) 후, 주소 공간을 할당한다. fork() 다음에 이어지는 exec() System Call을 통해 새로운 프로그램을 메모리에 올린다.
➳ 부모 프로세스 (parent process)가 자식 프로세스 (children process)를 생성한다.
• 운영체제에게 만들어달라고 요청한다. - fork() system Call
➳ 프로세스의 트리 (계층 구조)를 형성한다.
➳ 프로세스는 자원을 필요로 한다.
• 운영체제로부터 받는다.
• 부모와 공유한다.
➳ 자원의 공유
• 부모와 자식이 모든 자원을 공유하는 모델
• 일부를 공유하는 모델
• 전혀 공유하지 않는 모델
➳ 수행 (execution)
• 부모와 자식은 공존하며 수행되는 모델
• 자식이 종료 (terminate)될 때까지 부모가 기다리는 (wait) 모델
➳ 주소 공간 (address space)
• 자식은 부모의 공간을 복사한다. (biinary and OS data)
• 자식은 그 공간에 새로운 프로그램을 올린다.
➳ 유닉스의 예
• fork() System Call이 새로운 프로세스를 생성한다. 부모를 그대로 복사 (OS data except PID + binary) 후, 주소 공간을 할당한다.
• fork() 다음에 이어지는 exec()System Call을 통해 새로운 프로그램을 메모리에 올린다.
프로세스 종료 (Process Termination)
프로세스가 마지막 명령을 수행한 후 운영체제에게 이를 알려준다. (exit)
➳자식이 부모에게 output data를 보낸다. (viawait)
➳프로세스의 각종 자원들이 운영체제에게 반납된다.
부모 프로세스가 자식의 수행을 종료시킨다. (abort)
➳자식이 할당 자원의 한계치를 넘어선 경우
➳자식에게 할당된 task가 더 이상 필요하지 않은 경우
➳부모가 종료 (exit)하는 경우
•운영체제는 부모 프로세스가 종료하는 경우 자식이 더 이상 수행되도록 두지 않는다.
•단계적인 종료이다.
• e.g. 티스토리 글쓰기 창을 없애면 글쓰기 창 안의 여러 프로세스들도 동시에 없어지는 것과 같다.
fork( ) System Call
" create a child (copy) "
➳ A process is created by the fork() system call.
• creates a new address space that is a duplicate of the caller.
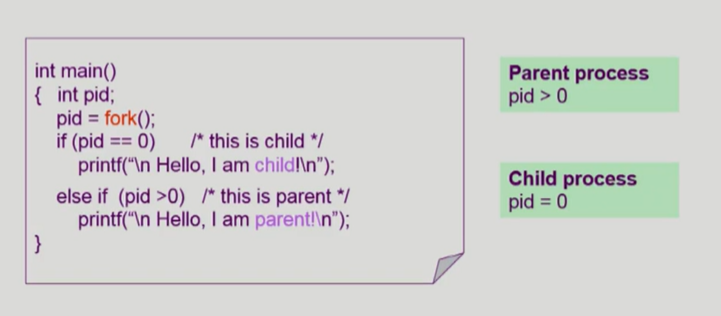
fork()는 자식을 하나 만들어달라고 요청하는 함수이다. fork() 하는 순간 아래와 같이 복제한다.
물론 메모리 공간, Program Counter도 복제한다.
부모와 자식 모두 fork() 한 다음부터 실행한다. 그리고 이 둘은 별개의 프로세스가 되는 것이다. 복제했기 때문에 내가 부모인지 자식인지 알 수가 없어 서로 구분할 필요가 있다. fork()를 호출한 return 값이 부모 프로세스는 양수 값, 자식 프로세스는 0이므로 이를 통해 구분이 가능하다.
fork()는 한 프로세스의 동일한 실행 파일을 실행한 것과 같다. 완전히 다른 프로그램을 실행하고 싶다면 fork() system call 로만은 어렵다. 새로운 프로그램을 덮어 씌우는 서비스가 필요한데, 이를 위한 것이 바로 exec() system call이다.
• pid = 프로세스 식별자
exec( ) System Call
" overlay new image "
➳ A process can execute a different program by the exec() system call.
• replaces the memory image of the caller with a new program.
wait( ) System Call
" sleep utill child is done "
프로세스 A가 wait() System Call을 호출하면
➳ 커널은 child가 종료될 때까지 프로세스 A를 sleep 시킨다. (block 상태)
➳ child process가 종료되면 커널은 프로세스 A를 깨운다. (ready 상태)
아래 프로세스의 상태를 살펴보면, 자식의 종료를 기다리며 block 상태가 되도록 하는 부분이 wait() system call이라고 볼 수 있다.
만약 wait() system call이 없다면 부모 프로세스와 자식 프로세스는 CPU를 먼저 차지하기 위해 서로 경쟁할 것이다. 하지만 부모 프로세스가 fork() 후, wait()를 호출한다면 자식이 종료될 따까지 부모는 block 상태에 있는 것이다.
exit( ) System Call
" frees all the resources, notify parent "
프로세스의 종료
🔮 자발적 종료
➳ 마지막 statement 수행 후 exit() system call을 통해 종료한다.
➳ 프로그램에 명시적으로 적어주지 않아도 main 함수가 리턴되는 위치에 컴파일러가 넣어준다.
🔮 비자발적 종료
➳ 부모 프로세스가 자식 프로세스를 강제 종료시키는 경우
• 자식 프로세스가 한계치를 넘어서는 자원을 요청하는 경우
• 자식에게 할당된 task가 더 이상 필요하지 않은 경우
➳ 키보드로 kill, break 등을 친 경우
➳ 부모가 종료하는 경우
• 부모 프로세스가 종료하기 전에 자식들이 먼저 종료된다.
프로세스 간 협력
✔독립적 프로세스 (Independent process)
프로세스는 각자의 주소 공간을 가지고 수행되므로 원칙적으로 하나의 프로세스는 다른 프로세스의 수행에 영향을 미치지 못한다.
✔협력 프로세스 (Cooperating process)
프로세스 협력 메커니즘을 통해 하나의 프로세스가 다른 프로세스의 수행에 영향을 미칠 수 있다.
✔프로세스 간 협력 메커니즘 (IPC, Interprocess Communication)
1) 메시지를 전달하는 방법
" message passing "
커널을 통해 메시지를 전달한다.
2) 주소 공간을 공유하는 방법
" shared memory "
서로 다른 프로세스 간에도 일부 주소 공간을 공유하게 하는 shared memory 메커니즘이 있다.
" thread "
thread는 사실상 하나의 프로세스이므로 프로세스 간 협력으로 보기는 어렵지만 동일한 프로세스를 구성하는 thread 간에는 주소 공간을 공유하므로 협력이 가능하다.
원칙적으로는 각 프로세스는 본인만의 code, data, stack만 접근할 수 있으므로 서로 다른 프로세스가 메모리 공간을 share 할 수 없다. Shared Memory를 위해 운영체제에게 system call로 부탁하는 것이다. 프로세스 간 서로 신뢰할 수 있는 경우에만 shared memory를 만들어야 한다.
Stack문제이다! 대표적인 Stack 유형 문제인 괄호 문제와 비슷하게 풀어주면 된다. 반복문을 활용해 문자열 s를 한 문자씩 char 변수로 떼어서 차례대로 검사한다. 해당 char 변수가 Stack에 들어있는 맨 위의 값과 동일하다면 stack.pop()을 하여 같은 알파벳이 2개 붙어 있는 짝을 제거하는 역할을 해주고, 그렇지 않다면 stack.push()를 한다. 만약 최종적으로 Stack이 비었다면 짝지어 제거하기를 성공적으로 수행한 것이므로 1을 리턴하고, 그렇지 않다면 0을 리턴해준다.
Key Point
🔑 Stack을 활용한다.
Java 코드
import java.util.*;
class Solution
{
public int solution(String s)
{
Stack<Character> stack = new Stack<>();
for (char c : s.toCharArray()) {
if(!stack.isEmpty() && stack.peek() == c) stack.pop();
else stack.push(c);
}
return stack.isEmpty() ? 1 : 0;
}
}
+
근데 이거 괄호가 왜 독특한지는 모르겠다 ,,?
뭔가 ,,, 괄호에게 한 칸 전부를 수여해주는 ,, 2017 팁스타운만의 차별화 방식인가 ,,,?
🦌 크리스마스 D-10 기념으로 트리에 대해서 알아보자 🎅🏻 물론 크리스마스 트리 말고 ,, 자료구조 트리이다 ^_^ 트리는 가계도와 같은 계층적인 구조를 표현할 때 사용할 수 있는 자료구조이다. 기본적으로 트리의 크기가 N일 때, 전체 간선의 개수는 N-1이다. 부모-자식 관계로 이루어져 있다. 트리 내에 하위 트리가 있고, 그 하위 트리 안에는 또 다른 하위 트리가 있는 재귀적 자료구조이기도 하다.
트리는 가계도와 같은 계층적인 구조를 표현할 때 사용할 수 있는 자료구조이다. 기본적으로 트리의 크기가 N일 때, 전체 간선의 개수는 N-1이다. 부모-자식 관계로 이루어져 있다. 트리 내에 하위 트리가 있고, 그 하위 트리 안에는 또 다른 하위 트리가 있는 재귀적 자료구조이기도 하다. 컴퓨터의 directory 구조가 트리 구조의 대표적인 예이다.
❄️ 루트 노드 (root node) : 부모가 없는 최상위 노드
❄️ 단말 노드 (leaf node) : 자식이 없는 노드
❄️ 크기 (size) : 트리에 포함된 모든 노드의 개수
❄️ 깊이 (depth) : 루트 노드부터의 거리 (= 간선의 수)
❄️ 높이 (height) : 깊이 중 최댓값
❄️ 차수 (degree) : 각 노드의 (자식 방향) 간선 개수 (= 하위 트리 개수)
이진 탐색 트리 (Binary Search Tree)
이진 탐색이 동작할 수 있도록 고안된 효율적인 탐색이 가능한 자료구조의 일종이다.
🔔 이진 탐색 트리의 특징 : 왼쪽 자식 노드 < 부모 노드 < 오른쪽 자식 노드
이진 탐색 트리가 이미 구성되어 있다면 데이터를 조회하는 방법은 다음과 같다.
🔔 루트 노드부터 방문하여 탐색을 진행한다.
🔔 현재 노드와 찾고자 하는 값을 비교한다.
🔔 원소를 찾았다면 탐색을 종료한다.
트리의 순회 (Tree Traversal)
트리 자료구조에 포함된 노드를 특정한 방법으로 한 번씩 방문하는 방법을 의미한다.
대표적인 트리 순회 방법은 다음과 같다.
🎄 전위 순회 (pre-order traverse) : 루트를 먼저 방문한다.
• 노드 - 왼쪽 자식 - 오른쪽 자식 순
🎄 중위 순회 (in-order traverse) : 왼쪽 자식을 방문한 뒤에 루트를 방문한다.
• 왼쪽 자식 - 노드 - 오른쪽 자식 순
🎄 후위 순회 (post- order traverse) : 오른쪽 자식을 방문한 뒤에 루트를 방문한다.
CPU는 하나이기 때문에 CPU에서 기계어를 실행하고 있는 프로세스는 매 순간 하나이다. 실행 중인 프로세스는 'Running 상태에 있다.'라고 표현한다. CPU를 쓰기 위해 기다리고 있는 프로세스는 Ready 상태라고 한다. 또한, CPU를 주어도 당장 기계어 실행이 불가능한 프로세스도 있다. 예를 들어 디스크에서 파일을 읽어야 한다면, 이 작업이 다 끝날 때까지는 CPU를 줘봐야 소용이 없다. 이처럼 CPU를 얻어도 무의미한 프로세스를 두고 Blocked 상태라고 한다.
프로세스의 상태를 나타내는 개념이 프로세스의 문맥이다. 즉, 프로세스의 문맥은 시간에 따라 현재 CPU를 얼마나 사용했는지, 메모리를 얼마나 가지고 있는지, 무슨 함수를 실행하고 있는지, 과거에 나쁜 짓은 하지 않았는지 (?) 등의 프로세스의 상태를 나타내는 정보이다. 운영체제는 프로세스의 문맥을 매우 중요하게 생각한다.
프로세스의 상태 (Process State)
CPU는 하나이기 때문에 CPU에서 기계어를 실행하고 있는 프로세스는 매 순간 하나이다. 실행 중인 프로세스는 'Running 상태에 있다.'라고 표현한다. CPU를 쓰기 위해 기다리고 있는 프로세스는 Ready 상태라고 한다. 또한, CPU를 주어도 당장 기계어 실행이 불가능한 프로세스도 있다. 예를 들어 디스크에서 파일을 읽어야 한다면, 이 작업이 다 끝날 때까지는 CPU를 줘봐야 소용이 없다. 이처럼 CPU를 얻어도 무의미한 프로세스를 두고 Blocked 상태라고 한다.
🔅 프로세스는 상태 (state)가 변경되며 수행된다.
➳ Running
• CPU를 잡고 instruction을 수행 중인 상태이다.
➳ Ready
• CPU를 기다리는 상태이다. (메모리 등 다른 조건은 모두 만족한 경우)
➳ Blocked (wait, sleep)
• CPU를 주어도 당장 instruction을 수행할 수 없는 상태이다.
• Process 자신이 요청한 event (ex) I/O)가 즉시 만족되지 않아 이를 기다리는 상태이다. (ex) 디스크에서 파일을 읽어와야 하는 경우)
➳ Suspended (stopped)
• 외부적인 이유로 프로세스의 수행이 정지된 상태이다. (중기 스케줄러에 의해 쫓겨난 상태)
• 프로세스는 통째로 디스크에 swap out 된다.
e.g. 사용자가 프로그램을 일시 정지시킨 경우 (break key) 시스템이 여러 이유로 프로세스를 잠시 중단시킨다.
(메모리에 너무 많은 프로세스가 올라와 있을 때)
Blocked: 자신이 요청한 event가 만족되면 Ready
Suspened : 외부에서 resume 해주어야 Active
✔ New : 프로세스가 생성중인 상태이다.
✔ Terminated : 수행(execution)이 끝난 상태이다.
운영체제는 PCB를 통해 각 프로세스의 상태를 일일이 관리한다. 또한, 자료구조 Queue를 사용해 줄을 세워두고 일을 처리한다.
Disk I/O queue에서 기다리던 프로세스가 디스크에서 파일을 다 읽었다면 Interrupt를 걸어 운영체제로 하여금 Ready queue에 넣도록 한다.
오래 걸리는 작업은 하드웨어뿐만 아니라 여러 프로세스가 동시에 사용하는 공유 데이터를 사용하는 것도 해당하며, 이 경우 역시 Blocked 상태이다.
프로세스 상태도
CPU scheduler가 ready 상태인 프로세스를 CPU에게 주면 running 상태가 되는 것이다. 프로세스가 CPU에서 기계어를 실행하다가 CPU를 내놓는 경우는 세 가지 경우가 있다. 할당 시간이 만료되어 Timer Interrupt가 발생하는 경우, I/O 혹은 event 작업을 기다리는 blocked 상태인 경우, 본인의 일을 다해서 종료 (terminated)되는 경우이다.
이 상태도는 running을 user mode와 monitor mode로 나누었다. 어떤 프로세스가 자기 코드를 수행 중이라면 user mode의 running이고, IO작업과 같이 본인이 할 수 없는 일을 운영체제에게 부탁하여(= System Call), 운영체제에서 코드를 수행 중이라면 monitor mode(= kernel mode)의 running이다.
그리고 이 상태도는 Suspended가 추가되었다. running, blocked, ready는 active 상태이지만, suspended는 inactive 상태이다.
프로그램의 실행
위의 그림에서는 모두 running 상태인 것이다.
Process Control Block (PCB)
운영체제가 각 프로세스를 관리하기 위해 프로세스 당 유지하는 정보로, 운영체제 커널 주소공간에 있다.
구조체로 유지하는 구성 요소는 아래와 같다.
(1) OS가 관리상 사용하는 정보
• Process state, Process ID
• scheduling information, priority
(2) CPU 수행 관련 하드웨어 값
• Program counter, registers
(3) 메모리 관련
• code, data, stack의 위치 정보
(4) 파일 관련
• Open file descriptors
(2)를 보면, CPU 수행 관련 하드웨어 값을 PCB에 또 저장한다. 프로세스는 CPU를 얻었다가 빼앗겼다가 하는데, 매번 CPU를 빼앗길 때에는 해당 프로세스가 어디까지 수행되었는지 저장해두기 위함이다. 즉, 문맥을 저장해두는 것이다. 이를 통해 다음번에 CPU를 얻었을 때 해당 문맥 바로 다음 지점을 실행할 수가 있다.
문맥 교환 (Context Switch)
➳ CPU를 한 프로세스에서 다른 프로세스로 넘겨주는 과정이다.
➳ registers뿐만 아니라 Memory map과 관련된 정보들도 save 하고, load 한다.
➳ CPU가 다른 프로세스에게 넘어갈 때 운영체제는 다음을 수행한다.
• CPU를 내어주는 프로세스의 상태를 그 프로세스의 PCB에 저장한다.
• CPU를 새롭게 얻는 프로세스의 상태를 PCB에서 읽어온다.
문맥 교환인 경우와 그렇지 않은 경우를 헷갈리지 않도록 조심해야 한다.
System call이나 Interrupt 발생 시 반드시 문맥 교환이 일어나는 것은 아니다.
다른 사용자 프로세스에게 CPU가 넘어가는 경우만 문맥 교환이라고 볼 수 있다.
(1)의 경우는 문맥 교환이 아니다. (1)의 경우에도 CPU 수행 정보 등 context의 일부를 PCB에 save 해야 하지만 문맥 교환을 하는 (2)의 경우에는 그 부담이 훨씬 크다. (e.g. cache memory flush)
프로세스를 스케줄링하기 위한 큐
프로세스들은각큐들을오가며수행된다.
➳ Job queue
• 현재 시스템 내에 있는 모든 프로세스의 집합이다.
➳ Ready queue
• 현재 메모리 내에 있으면서 CPU를 잡아서 실행되기를 기다리는 프로세스의 집합이다.
➳ Device queue
• I/O device의 처리를 기다리는 프로세스의 집합이다.
ReadyQueue와 다양한 Device Queue
프로세스 스케줄링 큐의 모습
스케줄러 (Scheduler)
운영체제에서 스케줄링을 하는 함수 혹은 코드라고 볼 수 있다. 특정 기능을 수행하므로 스케줄러라고 명명하였다.
사실은 운영체제라고 볼 수 있다는 뜻이다.
✔ Long-term scheduler (장기 스케줄러, job scheduler)
➳ 시작 프로세스 중 어떤 것들을ready queue로 보낼지 결정한다.
➳프로세스에memory(및 각종 자원)를 주는 문제를 담당한다.
➳degree of Multiprogramming을 제어한다.
• 메모리에 올라가 있는 프로그램의 수
➳time sharing system에는 보통 장기 스케줄러가 없다. (무조건 ready)
•time sharing system이전의 옛날 시스템에서 사용했다.
• 현대 운영체제는 장기 스케줄러가 없는 대신 중기 스케줄러를 둔다.
✔ Short-term scheduler (단기 스케줄러, CPU scheduler)
➳어떤 프로세스를 다음번에running시킬지 결정한다.
➳프로세스에CPU를 주는 문제를 담당한다.
➳ 자주 호출이 되므로, 충분히 빨라야 한다. (millisecond 단위)
✔ Medium-term scheduler (중기 스케줄러 or Swapper)
➳여유 공간 마련을 위해 프로세스를 통째로 메모리에서 디스크로 쫓아낸다.
➳프로세스에게서memory를 뺏는 문제를 담당한다.
➳degree of Multiprogramming을 제어한다.
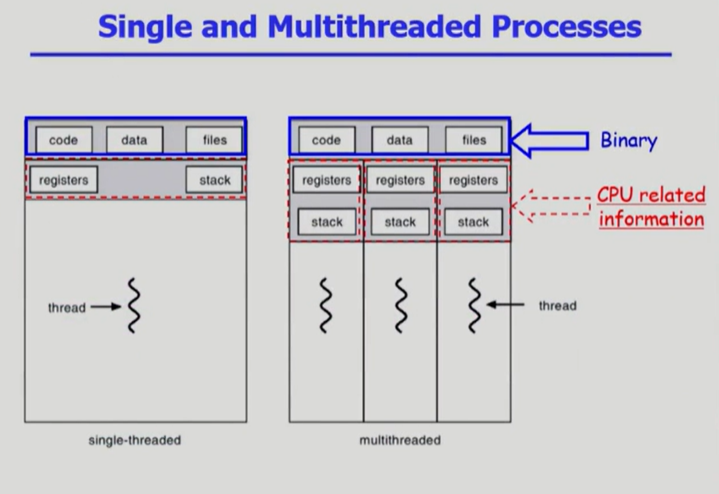
스레드 (Thread)
"A thread (or lightweight process) is a basic unit of CPU utilization "
Thread의 구성
➳ program counter
➳ register set
➳ stack space
Thread가동료thread와공유하는 부분 (= task)
➳ code section
➳ data section
➳ OS resources
전통적인 개념의 heavyweight process는 하나의 Process가 하나의 thread를 가지고 있는 task로 볼 수 있다.
Benefits of Threads
➳ Responsiveness
• e.g. multi-threaded Web - if one thread is blocked (e.g. network) another thread continues (e.g. display)
➳ Resource Sharing
• n threads can share binary code, data, resource of the process
➳ Economy
• creating & CPU switching thread (rather than a process)
• Solaris의 경우 위 두 가지 overhead가 각각 30배, 5배
➳ Utilization of MP Architectures
• each thread may be running in parallel on a different processor
🚀
다중 스레드로 구성된 task 구조에서는 하나의 서버 스레드가 blocked (waiting) 상태인 동안에도
동일한 task 내의 다른 스레드가 실행 (running)되어 빠른 처리를 할 수 있다.
🚀
동일한 일을 수행하는 다중 스레드가 협력하여 높은 처리율 (throughput)과 성능 향상을 얻을 수있다.
🚀
스레드를 사용하면 병렬성을 높일 수 있다.
Implementation of Threads
➳ Some are supported by kernel -Kernel Threads
• Windows 95/98/NT
• Solaris
• Digital UNIX, Mach
➳ Others are supported by library - User Threads
• POSIX Pthreads
• Mach C-threads
• Solaris threads
➳ Some are real-time threads
Process와 Thread
Process
우리는 웹 브라우저를 여러 개 띄워놓고 실행할 수 있다. 동일한 웹 브라우저 프로그램이지만 여러 개 띄워놓으면 여러 프로세스가 된다. 각각 프로세스마다 주소공간과 PCB가 하나씩 만들어질 것이다. 각각의 프로세스가 만들어지고, 각각 메모리에 올라가는 것은 비효율적이다. 여러 개 띄우더라도 같은 프로그램이므로 동일한 코드를 가지고 있을 것이다. 이를 좀 더 효율적으로 운용할 수 없을까?
Thread
위의 방법보다 훨씬 효율적인 방법은 바로 Thread이다. Thread는 동일한 프로그램을 여러 개 띄우더라도 하나의 프로세스만 만들어지는 것이다. code와 같이 동일한 부분들을 한 번에 share 한다. 대신 여러 개 띄워놓은 각각의 프로그램은 서로 다른 부분의 코드를 수행할 수도 있다. 그 부분만 따로 관리를 해주기 위해 CPU의 수행단위, 즉 현재 CPU의 어느 부분을 실행하고 있는가와 관련된 정보만 따로 둔다. PCB에서 코드의 어느 부분을 수행하고 있는가에 해당하는 Program Counter 값은 각각의 Thread로 나누어 각각의 위치를 나타내고, registers 값도 현재 CPU에서 연산을 하면서 각자 CPU 수행단위가 따로 있으니까 따로 둔다. 각 Thread는 CPU를 얻었을 때 코드의 어느 부분을 실행하기 위해 함수를 호출하면서 Stack에 쌓이게 되고, 이 또한 별도로 관리한다.
" Thread는 overhead를 줄여준다. "
프로세스 A에서 프로세스 B로 CPU를 넘겨주는 것을 문맥 교환 (Context Switch)이라고 한다. 이는 대단히 오버헤드(overhead)가 많은 작업이다. overhead란 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 및 메모리 등을 말한다. 동일한 프로세스 안에서 Thread1 로부터 Thread2 에게 CPU를 넘겨주는 것은 Context Switch의 값비싼 overhead가 필요가 없다. 따라서 효율적이다.
" Thread는 Process보다 효율적이다. "
그러나 크롬 브라우저는 보안 상의 문제로 여러 개의 창을 띄우는 것을 Thread가 아니라 Process로 한다는 이야기도 있다고 한다.
compareTo 메서드는 알고리즘을 풀면서 몇 번 사용한 적이 있지만 Comparable과 Comparator 인터페이스는 처음 접해보았다 ,, 아니면 까먹었거나 ,,^^ 인터페이스 사용법을 검색하다가 우연히 "문자열 내 마음대로 정렬하기" 문제를 만났다. 문제가 훨씬 직관적이어서 이 문제를 먼저 풀고 나니 Java에서의 객체 정렬을 이해하는데 도움이 되었다.
Java 코드
import java.util.*;
class Solution {
public String[] solution(String[] strings, int n) {
Arrays.sort(strings, new Comparator<String>() {
// 앞의 값(o1)과 뒤의 값(o2)을 비교해서 리턴값을 양수로 주면 값을 바꾼다. (오름차순)
// 앞의 값(o1)과 뒤의 값(o2)을 비교해서 리턴값을 음수로 주면 값을 바꾸지 않는다. (내림차순)
@Override
public int compare(String o1, String o2) {
if (o1.charAt(n) > o2.charAt(n)) {
return 1;
}
else if (o1.charAt(n) == o2.charAt(n)) {
// compareTo() 함수는 두 개의 값을 비교하여 int 값으로 반환해준다.
return o1.compareTo(o2);
}
else {
return -1;
}
}
});
return strings;
}
}