


목차
운영체제 (Operating System, OS) 란 ?
컴퓨터 하드웨어 바로 위에 설치되어 사용자 및 다른 모든 소프트웨어와 하드웨어를 연결하는 소프트웨어 계층이다. 운영체제 중 항상 필요한 부분은 전원이 켜짐과 동시에 메모리에 올려 놓고, 그렇지 않은 부분은 필요할 때 메모리로 올려 사용한다.
협의의 운영체제 (= 커널)
➳ 운영체제의 핵심 부분으로 메모리에 상주하는 부분이다.
광의의 운영체제
➳ 커널뿐 아니라 각종 주변 시스템 유틸리티(ex) 파일 복사 프로그램) 등을 포함한 개념이다.
➳ 필요할 때만 메모리에 올라가는 별도의 프로그램이다.
운영체제의 목적

🔅 컴퓨터 시스템을 편리하게 사용할 수 있는 환경을 제공한다.
➳ 운영체제는 동시 사용자 및 프로그램들이 각각 독자적 컴퓨터에서 수행되는 것 같은 환상을 제공한다.
➳ 하드웨어를 직접 다루는 복잡한 부분을 운영체제가 대행한다.
• 따라서 사용자 및 프로그램은 쉽게 프로그램 실행이 가능하다.
• ex) 사용자는 파일이 디스크에 어떻게 저장되는지 몰라도 쉽게 파일을 저장한다.
🔅 컴퓨터 시스템의 자원을 효율적으로 관리한다.
➳ 자원이란 CPU, 메모리, 하드디스크 등 하드웨어 자원뿐 아니라 소프트웨어 자원까지 통칭해서 부른다.
➳ 프로세서, 기억장치, 입출력 장치 등을 효율적으로 관리한다.
• 사용자 간의 형평성 있는 자원 분배를 지향한다.
• 주어진 자원으로 최대한의 성능을 내도록 한다.
➳ 프로세스, 파일, 메시지 등을 관리한다.
➳ 사용자와 운영체제 자신을 보호한다.
여러 사용자의 프로그램이 하나의 컴퓨터에서 실행될 때,
A사용자가 B사용자의 프로그램이 올라가 있는 메모리 영역을 침범하거나 특정 파일에 접근하는 일이 생기면 안 된다.
운영체제의 분류
운영체제의 분류는 크게 아래 세 가지로 나누어 볼 수 있다.
노란색으로 표시한 것은 요즘 대부분의 운영체제가 채택한 것이다.
1. 동시 작업 가능 여부
1) 단일 작업 (single tasking)
➳ 한 번에 하나의 작업만 처리한다.
➳ 한 명령의 수행이 끝나기 전에 다른 명령을 수행할 수 없다.
ex) MS-DOS
2) 다중 작업 (multi tasking)
➳ 동시에 두 개 이상의 작업만 처리한다.
➳ 한 명령의 수행이 끝나기 전에 다른 명령을 수행할 수 있다.
➳ 현대적인 운영체제이다.
ex) UNIX, MS Windows
2. 사용자의 수
1) 단일 사용자 (single user)
➳ 한 번에 한 명의 사용자만이 사용할 수 있다.
ex) MS-DOS, MS Windows
2) 다중 사용자 (multi user)
➳ 여러 사용자가 동시에 접속해 사용할 수 있다.
ex) UNIX, NT server
3. 처리 방식
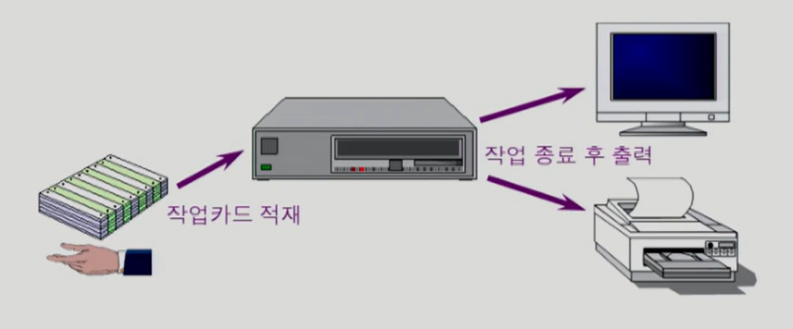
1) 일괄 처리 (batch processing)
➳ 작업 요청의 일정량을 모아서 한꺼번에 처리한다.
➳ 작업이 완전 종료될 때까지 기다려야 한다.
ex) 초기 Punch Card 처리 시스템
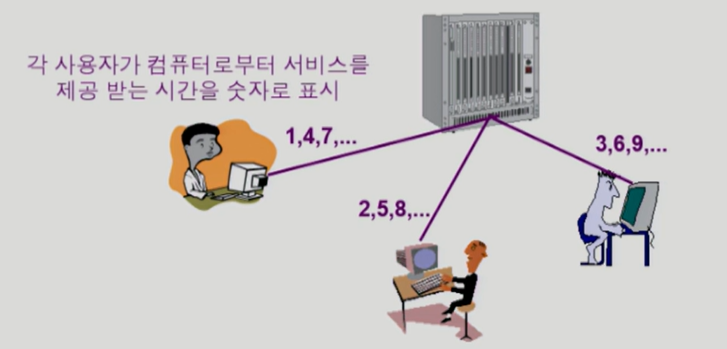
2) 시분할 (time sharing)
➳ 여러 작업을 수행할 때 컴퓨터 처리 능력을 일정한 시간 단위로 분할하여 사용한다.
➳ 일괄 처리 시스템에 비해 짧은 응답 시간을 가진다.
➳ Interactrive한 방식이다.
➳ 사용자의 요청에 대한 결과를 곧바로 얻을 수 있는 대화형 시스템으로, 사람이 느끼기에 빠르면서 동시에 효율적인 것이 목표이다.
ex) UNIX
3) 실시간 (realtime OS)
➳ 정해진 시간 안에 어떠한 일이 반드시 종료됨이 보장되어야하는 실시간시스템을 위한 OS이다.
ex) 원자로/공장 제어, 미사일 제어, 반도체 장비, 로보트 제어
➳ 실시간 시스템의 개념 확장
• Hard realtime system (경성 실시간 시스템)
• Soft realtime system (연성 실시간 시스템) - ex) 유튜브와 같은 멀티미디어 스트리밍 시스템
💡 몇 가지 용어를 알아보자 !
- Multitasking
- Multiprogramming
- Time Sharing
- Multiprocess
➳ 위의 용어들은 컴퓨터에서 여러 작업을 동시에 수행하는 것을 뜻한다.
• Multiprogramming은 여러 프로그램이 메모리에 올라가 있음을 강조한다.
• Time Sharing은 CPU의 시간을 분할하여 나누어 쓴다는 의미를 강조한다.
아래에는 비슷해보이지만 전혀 의미가 다른 주의해야할 단어가 하나 있다.
✔ Multiprocessor : 하나의 컴퓨터에 CPU(processor)가 여러 개 붙어 있음을 의미한다.
운영체제의 예
🔅 DOS (Disk Operating System)
➳ MS사에서 1981년 IBM-PC를 위해 개발
➳ 단일 사용자용 운영체제, 메모리 관리 능력의 한계 (주 기억장치 : 640KB)
🔅 MS Windows
➳ MS사의 다중 작업용 GUI 기반 운영 체제
➳ Plug and Play, 네트워크 환경 강화
➳ DOS용 응용 프로그램과 호환성 제공
➳ 불안정성
➳ 풍부한 자원 소프트웨어
🔅 유닉스 (UNIX)
➳ 코드의 대부분을 C언어로 작성
➳ 높은 이식성
➳ 최소한의 커널 구조
➳ 복잡한 시스템에 맞게 확장 용이
➳ 소스 코드 공개
➳ 프로그램 개발에 용이
➳ 다양한 버전
• System V, FreeBSD, SunOS, Solaris
• Linux
Reference
KOCW 운영체제 강의 (이화여자대학교, 반효경 교수님)
'CS > OS' 카테고리의 다른 글
| 프로세스 동기화 (Process Synchronization) (0) | 2022.12.28 |
|---|---|
| CPU 스케줄링 (1) | 2022.12.26 |
| 프로세스의 생성과 종료 with System Call (0) | 2022.12.19 |
| 프로세스 (Process)와 스레드 (Thread) (0) | 2022.12.14 |
| 컴퓨터 시스템의 구조에 대하여 (0) | 2022.12.11 |
















